CX-0059 Use Case Behaviour Twin Endurance Predictor v2.0.1
ABSTRACT
Behavioral product models, built on a consistent architecture of reusable functional components within ecosystems like Catena-X, unlock a wide range of innovative business ideas and digital services.
The focus of the 'data-centric and model-centric development and operational support' revolves around the 'digital behaviour twin'. This concept maps products, their functions, attributes, and business metrics by using a shared data model.
Part of this digital twin involves dynamic services providing real-time information about existing or planned vehicles. Stakeholders like automobile clubs or recycler seek specific details, such as a component's expected lifespan. This information is crucial for determining the viability of recycling components.
This standard focuses on the Endurance Predictor. The Endurance predictor receives load spectra, which has been recorded in the vehicle, through the Catena-X network. The load spectra, combined with additional product knowledge by the service provider, is used to calculate precise remaining useful life values for specific components.
FOR WHOM IS THE STANDARD DESIGNED
The standard is relevant for the following roles within the scope of the Endurance Predictor service:
- data & service provider/consumer
- business application provider
COMPARISON WITH THE PREVIOUS VERSION OF THE STANDARD
This standard upgrades the triangle (previously CX-0059:1.2) to an Use Case Standard and consolidates the contents of the previously independent standards CX-0056, CX-0057 and CX-0058 within a single comprehensive standard.
1 INTRODUCTION
This document acts as an umbrella for single standards required to request "Remaining Useful Life (RUL)" data as well as providing a service for its calculation at a component level. Included are APIsAPI An API is a way for two or more computer programs to communicate with each other. to be provided by the service provider and the service requester, as well as aspect modelsAspect Model A formal, machine-readable semantic description (expressed with RDF/Turtle) of data accessible from an aspect. Note 1: An Aspect Model must adhere to the Semantic Aspect Meta Model (SAMM) and be compliant with its validity rules. Note 2: Aspect Models are logical data models that can be used to detail a conceptual model to describe the semantics of runtime data related to a concept; elements of an Aspect Model can/should refer to terms of a standardized Business Glossary (if existing). for the respective payloads being exchanged in an asynchronous pattern leveraging those APIsAPI An API is a way for two or more computer programs to communicate with each other..
1.1 AUDIENCE & SCOPE
This section is non-normative
The standard is relevant for the following roles within the scope of Endurance Predictor service:
- data & consumer provider/consumer
- business application provider
NOTE: Fulfilling a use case standard by a data provider/consumer can be done in two ways: A) purchase a certified app for the use case. In this case the data provider/consumer does not need to proof conformity again and B) data provisioning/consumption without a certified app for the use case. In this case the data provider/consumer needs to proof conformity with all single standards listed in this document.
1.2 CONTEXT AND ARCHITECTURE FIT
This section is non-normative
There are two ways for implementing the Remaining useful Life (RuL) use case:
- Using the Knowledge Agent technology.
- Using the notification based APIAPI An API is a way for two or more computer programs to communicate with each other. directly.
In order to be scalable (multiple partners/components), the preferred way is to use the Knowledge Agent.
1.2.1 KNOWLEDGE AGENT
This graphic illustrates the principles architecture of the Endurance Predictor Service using the Knowledge Agent.
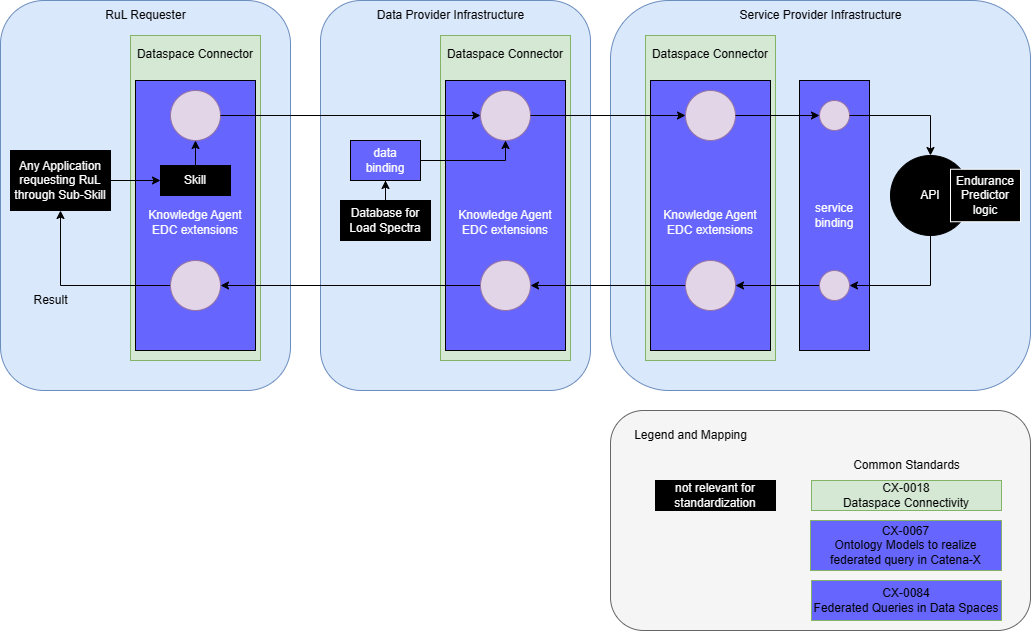
Since Data Transfer in Catena-X requires IDSAIDSA The IDSA is an organization working to create the future of the global digital economy with International Data Spaces (IDS): a secure, sovereign system of data sharing where participants can realize the full value of their data. compliance, both parties involved must use an IDSAIDSA The IDSA is an organization working to create the future of the global digital economy with International Data Spaces (IDS): a secure, sovereign system of data sharing where participants can realize the full value of their data. compliant connector and provision the APIAPI An API is a way for two or more computer programs to communicate with each other. endpoints as specific data assetsAsset On the Data Provider side, an Asset describes the data set which will be shared or can be consumed by a Data Consumer. in those connectors.
The Knowledge Agent functionality for the Dataspace Connector is required. This is defined in CX-0084:v1.2 Federated Queries in Data Spaces.
A standard for a semantic-driven and state-of-the-art compute-to-data architecture for Catena-X, the so-called Knowledge Agents (KA) approach. It builds on well-established W3C-standards of the semantic web.
Depending on your role, you must provide the following parts of this standard:
- all:
- running Knowledge Agent Dataspace Connector extensions
- data provider:
- bindings for load spectra to the knowledge graph, ideally by using a binding agent (see Binding Layer and related examples in CX-0084:v1.2)
- graph assetAsset On the Data Provider side, an Asset describes the data set which will be shared or can be consumed by a Data Consumer., which describes and offers the data bindings in a Knowledge Agent compatible way (policies may also be required)
- optional: a RuL skill (if you want to provide simple access to RuL calculations for yourself or for external requesters)
- service provider
- bindings for a endurance predictor service (see cx-behaviour:RemainingUsefulLife within the behaviour ontology) to the knowledge graph, ideally by using a binding agent
- graph assetAsset On the Data Provider side, an Asset describes the data set which will be shared or can be consumed by a Data Consumer., which describes and offers the service bindings in a Knowledge Agent compatible way (policies may also be required)
- service requester
- an own RuL skill or a access to a remote skill
If a service requester requests a RuL value, he invokes the RuL skill and provides a vehicle identification number to it. This can also be done for multiple vehicles at once in a batch mode. The skill is located at or transferred to the data provider. At the data provider, the data bindings and the service provider are resolved by the Knowledge Agent. Then, the data are transferred to the service provider via Knowledge Agent. There, the RuL value is calculated and passed back to the requester.
Although it is not mandatory to use the Endurance Predictor APIAPI An API is a way for two or more computer programs to communicate with each other. (section 4) and the Aspect modelsAspect Model A formal, machine-readable semantic description (expressed with RDF/Turtle) of data accessible from an aspect. Note 1: An Aspect Model must adhere to the Semantic Aspect Meta Model (SAMM) and be compliant with its validity rules. Note 2: Aspect Models are logical data models that can be used to detail a conceptual model to describe the semantics of runtime data related to a concept; elements of an Aspect Model can/should refer to terms of a standardized Business Glossary (if existing). (section 3) in the Knowledge Agent context, it is recommended to do so.
1.2.2 NOTIFICATION BASED API
This graphic illustrates the principles architecture of the Endurance Predictor Service using the notification based APIAPI An API is a way for two or more computer programs to communicate with each other..
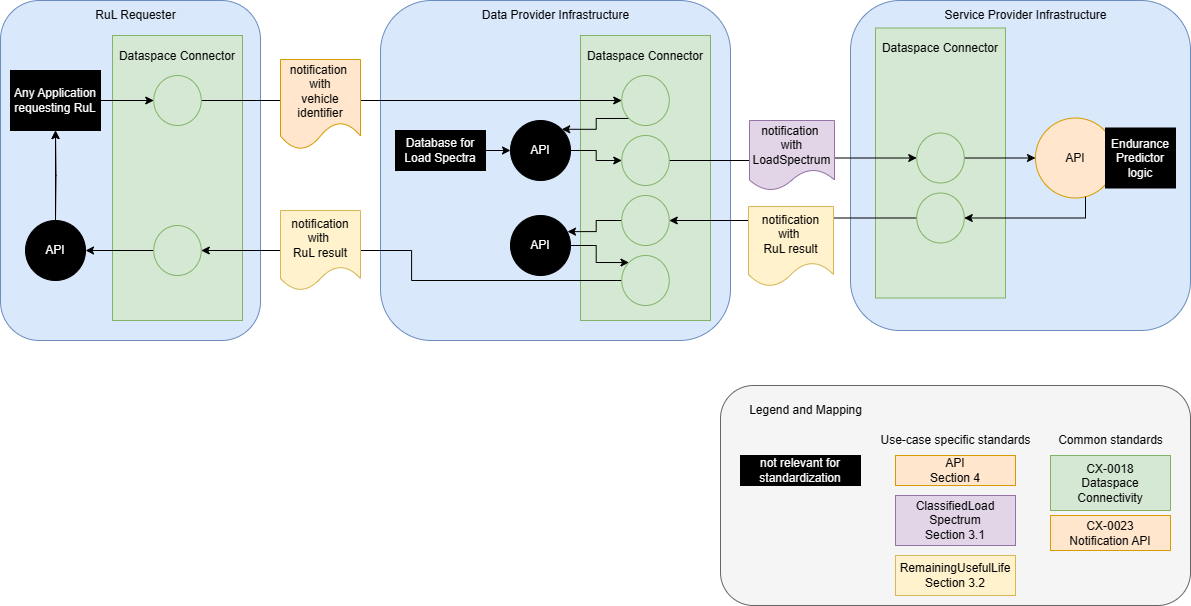
As a data provider you will receive a request for remaining useful life information from an outside RuL service requester via Dataspace Connector. The data provider, which has the vehicle load spectrum data, forwards them by calling the supplierSupplier In the context of OSim, the producer of goods. of the specific part. After the calculation, the results are transferred back to the data provider through the Dataspace Connector and forwarded to the requester.
The present standard (CX-0138) contains two aspect modelsAspect Model A formal, machine-readable semantic description (expressed with RDF/Turtle) of data accessible from an aspect. Note 1: An Aspect Model must adhere to the Semantic Aspect Meta Model (SAMM) and be compliant with its validity rules. Note 2: Aspect Models are logical data models that can be used to detail a conceptual model to describe the semantics of runtime data related to a concept; elements of an Aspect Model can/should refer to terms of a standardized Business Glossary (if existing). described in detail in Chapter 3.
- Aspect ModelAspect Model A formal, machine-readable semantic description (expressed with RDF/Turtle) of data accessible from an aspect. Note 1: An Aspect Model must adhere to the Semantic Aspect Meta Model (SAMM) and be compliant with its validity rules. Note 2: Aspect Models are logical data models that can be used to detail a conceptual model to describe the semantics of runtime data related to a concept; elements of an Aspect Model can/should refer to terms of a standardized Business Glossary (if existing). for load spectra, acting as the main input for a component specific calculation for remaining useful life. (See section 3.1)
- Aspect ModelAspect Model A formal, machine-readable semantic description (expressed with RDF/Turtle) of data accessible from an aspect. Note 1: An Aspect Model must adhere to the Semantic Aspect Meta Model (SAMM) and be compliant with its validity rules. Note 2: Aspect Models are logical data models that can be used to detail a conceptual model to describe the semantics of runtime data related to a concept; elements of an Aspect Model can/should refer to terms of a standardized Business Glossary (if existing). for Remaining Useful Life data, acting as the main output for a component specific calculation for remaining useful life. (See section 3.2)
It also contains the APIAPI An API is a way for two or more computer programs to communicate with each other. descriptions for the APIsAPI An API is a way for two or more computer programs to communicate with each other. to exchange requests as well as results of a remaining useful life calculation:
- APIAPI An API is a way for two or more computer programs to communicate with each other. Endurance Predictor (contains both APIAPI An API is a way for two or more computer programs to communicate with each other. descriptions). (See section 4.1)
The calculation and data transfers are asynchronous, therefore all parties involved in a calculation request require to provide notification APIAPI An API is a way for two or more computer programs to communicate with each other. endpoints, as the results are sent back at a later stage and not as part of the HTTPHTTP HTTP is an application-layer protocol for transmitting hypermedia documents (such as HTML). It was designed for communication between web browsers and web servers, but can also be used for other purposes. response body. The notification formats are covered by CX-0023 Notification APIAPI An API is a way for two or more computer programs to communicate with each other..
Since Data Transfer in Catena-X requires IDSAIDSA The IDSA is an organization working to create the future of the global digital economy with International Data Spaces (IDS): a secure, sovereign system of data sharing where participants can realize the full value of their data. compliance, both parties involved must use an IDSAIDSA The IDSA is an organization working to create the future of the global digital economy with International Data Spaces (IDS): a secure, sovereign system of data sharing where participants can realize the full value of their data. compliant connector and provision the APIAPI An API is a way for two or more computer programs to communicate with each other. endpoints as specific data assetsAsset On the Data Provider side, an Asset describes the data set which will be shared or can be consumed by a Data Consumer. in those connectors.
1.3 CONFORMANCE AND PROOF OF CONFORMITY
This section is non-normative
All participants and their solutions will need to proof, that they are conform with the Catena-X standards. To validate that the standards are applied correctly, Catena-X employs Conformity Assessment Bodies (CABs). Since this document describes a set of standards to be fulfilled, participants MUST fulfill all mentioned standards and the respective conformity assessment criteria in addition to the specific criteria mentioned in this document. The specific criteria described in this document are describing the usage of the central tools as well as common tools described in the linked standardization documents and therefore compliance should be checked with the tools provided for these components. The Tractus-X EDCTractus-X EDC The Tractus-X Eclipse Dataspace Connector (Tractus-X EDC) is a reference implementation for a connector conformant to CX-0018 and acts as a de-facto standard/reference implementation within Catena-X; other CX-0018-conformant connectors are also valid options. (Eclipse Dataspace Connector) is RECOMMENDED to be used as an IDSAIDSA The IDSA is an organization working to create the future of the global digital economy with International Data Spaces (IDS): a secure, sovereign system of data sharing where participants can realize the full value of their data. compliant connector, as it is the current reference implementation of the IDSA protocolIDSA Protocol The protocol used for data exchange in an International Dataspace; this includes contract negotiation..
1.4 EXAMPLES
The Endurance Predictor can be used in many different contexts.
OEM, TIER-X: In the early development phase, components can be designed using digital prototypes based on component-specific damage calculation. The load data required for this comes from simulation or measurement in the digital twin.
TIER-X: The overall product range becomes more attractive in the offer phase when model-based damage calculation is included as a product-related service.
During the usage phase, OEMs, car dealers and automotive clubs can further interpret the Remaining Useful Life calculation for a vehicle evaluation and offer it as vehicle-related services for their end customersCustomer In the context of OSim, the receiver of produced goods from a supplier. and fleet operators.
Even during the usage phase, but particularly during the recycling phase, OEMs, TIER-X, automotive clubs, car dealers, insurers, fleet operators and recyclers benefit from precise residual value analyses of the entire vehicle and its components based on component-specific damage calculation.
1.5 TERMINOLOGY
This section is non-normative
- Business Partner Number (BPNBPN A BPN is the unique identifier of a partner within Catena-X.): A BPNBPN A BPN is the unique identifier of a partner within Catena-X. is the unique identifier of a partner within Catena-X
- Tractus-X EDCTractus-X EDC The Tractus-X Eclipse Dataspace Connector (Tractus-X EDC) is a reference implementation for a connector conformant to CX-0018 and acts as a de-facto standard/reference implementation within Catena-X; other CX-0018-conformant connectors are also valid options. (Eclipse Dataspace Connector): The Tractus-X EDCTractus-X EDC The Tractus-X Eclipse Dataspace Connector (Tractus-X EDC) is a reference implementation for a connector conformant to CX-0018 and acts as a de-facto standard/reference implementation within Catena-X; other CX-0018-conformant connectors are also valid options. is a reference implementation of a connector for IDSAIDSA The IDSA is an organization working to create the future of the global digital economy with International Data Spaces (IDS): a secure, sovereign system of data sharing where participants can realize the full value of their data. conform sovereign data exchange
- Behaviour Twin: Behavioral product models, based on a structured and consistent architecture of reusable and standard functional components and applied in a common ecosystem.
- Notification: Notification - as described in CX-0023 Notification APIAPI An API is a way for two or more computer programs to communicate with each other. v1.2.2, are - in contrast to classical data offers in Catena-X - a way to push data from a sender to a receiver and vice versa in asynchronous way.
- Knowledge Agent (KA): The so-called Knowledge Agents (KA) approach. It builds on well-established W3C-standards of the semantic web, such as OWL, SPARQL, SHACL, RDF etc. and makes these protocols usable to formulate powerful queries to the data space. Those queries can be used to answer business questions directly (comparable to a search engine) or they can be embedded in apps to include query results into workflows with more advanced visualization.
- Matchmaking Agent: This component supports SparQL to traverse the federated data space as a large data structure. It interacts with the Dataspace Connector. The provider's Matchmaking Agent will be activated by its Dataspace Connector. Therefore, the Dataspace Connector must offer a Graph AssetAsset On the Data Provider side, an Asset describes the data set which will be shared or can be consumed by a Data Consumer. (variant of ordinary data assetsAsset On the Data Provider side, an Asset describes the data set which will be shared or can be consumed by a Data Consumer. in the Catena-X Dataspace Connectivity standard). The consumer's Matchmaking Agent interacts with its Dataspace Connector to negotiate and perform the transfer of Sub-Skills to other dataspace participants. The Matchmaking Agents are matching the (sub)graphs and negotiate appropriated graph assetsAsset On the Data Provider side, an Asset describes the data set which will be shared or can be consumed by a Data Consumer. with the partner Dataspace Connectors.
- Binding Agent: The Binding Agent is a restricted version of the Matchmaking Agent (subset of OWL/SparQL, e.g., without federation) which is just focused on translating Sub-Skills of a particular business domain (Bill-Of-Material, Chemical Materials, Production Sites, etc.) into proper SQL- or RESTREST An architectural style for designing networked applications. based backend system calls. Implementation details: For data bindings, OnTop is used. For service bindings, RDF4J is used.
- Ontology: The ontology is a formal representation of knowledge that captures concepts, relationships, and properties. It allows a shared understanding and reasoning about the respective domain. It must be hosted in a way that all participants can access it. Currently, the ontology is hosted at GitHub.
Use case specific glossary of used APIAPI An API is a way for two or more computer programs to communicate with each other. and SAMM models can be found in the respective sections in this standard document.
2 RELEVANT PARTS OF THE STANDARD "Use Case Behaviour Twin Endurance Predictor"
This section is normative
2.1 STANDARDS FOR "Use Case Behaviour Twin Endurance Predictor"
This section is normative
If using the Knowledge Agent, only external standards are used. The following internal standards only apply when using the notification based APIAPI An API is a way for two or more computer programs to communicate with each other..
As a Service Provider for an Endurance Predictor Service I need to fulfill the following standards in the following contexts:
- Semantic Model: Classified load spectrum (Section 3.1) MUST be understood by my service and MUST be consumed by my service provider APIAPI An API is a way for two or more computer programs to communicate with each other..
- Semantic Model: Remaining Useful Life (Section 3.2) MUST be provided as part of my communication of the result towards the requester and/or requesting application.
- APIAPI An API is a way for two or more computer programs to communicate with each other.: Endurance Predictor (Section 4.1) MUST be followed in terms of all relevant parts for a service provider.
As a Service Requester or Service Requester Application I need to fulfill the following standards in the following contexts:
- Semantic Model: Classified load spectrum (Section 3.1) MUST be provided as part of the request for a remaining useful life calculation towards a service operator's APIAPI An API is a way for two or more computer programs to communicate with each other..
- Semantic Model: Remaining Useful Life (Section 3.2) MUST be consumable by my connected underlying application.
- APIAPI An API is a way for two or more computer programs to communicate with each other.: Endurance Predictor (Section 4.1) MUST be followed in terms of all relevant parts for a service requester.
2.1.1 LIST OF STANDALONE STANDARDS
To participate in the Use Case Behaviour Twin Endurance Predictor, the following single standards MUST be fulfilled, depending on the usage of the Knowledge Agent:
- CX-0018:v3.0 Dataspace Connectivity
- CX-0023:v1.2 Notification APIAPI An API is a way for two or more computer programs to communicate with each other. (only if using the notification based APIAPI An API is a way for two or more computer programs to communicate with each other.)
- CX-0067:v1.1 Ontology Models to realize federated query in Catena-X (only if using the Knowledge Agent)
- CX-0084:v1.2 Federated Queries in Data Spaces (only if using the Knowledge Agent)
2.1.2 DATA REQUIRED
As a service requester or service requester application I MUST provide load spectra. If using the notification based APIAPI An API is a way for two or more computer programs to communicate with each other., the data MUST be in the format of the aspect modelAspect Model A formal, machine-readable semantic description (expressed with RDF/Turtle) of data accessible from an aspect. Note 1: An Aspect Model must adhere to the Semantic Aspect Meta Model (SAMM) and be compliant with its validity rules. Note 2: Aspect Models are logical data models that can be used to detail a conceptual model to describe the semantics of runtime data related to a concept; elements of an Aspect Model can/should refer to terms of a standardized Business Glossary (if existing). described in Section 3.1. As a service provider I MUST provide Remaining useful Life information. If using the notification based APIAPI An API is a way for two or more computer programs to communicate with each other., the results MUST be in the format of the aspect modelAspect Model A formal, machine-readable semantic description (expressed with RDF/Turtle) of data accessible from an aspect. Note 1: An Aspect Model must adhere to the Semantic Aspect Meta Model (SAMM) and be compliant with its validity rules. Note 2: Aspect Models are logical data models that can be used to detail a conceptual model to describe the semantics of runtime data related to a concept; elements of an Aspect Model can/should refer to terms of a standardized Business Glossary (if existing). described in Section 3.2.
2.1.3 ADDITIONAL REQUIREMENTS
KNOWLEDGE AGENT SPECIFIC REQUIREMENTS
The following only applies if you use the Knowledge Agent for the RuL use case.
If you are engaged as a data provider, you MUST mount your data source to the federated knowledge graph as Graph AssetAsset On the Data Provider side, an Asset describes the data set which will be shared or can be consumed by a Data Consumer.. Beside the policy and contract definition, a Graph AssetAsset On the Data Provider side, an Asset describes the data set which will be shared or can be consumed by a Data Consumer. registration is needed. As a service provider you MUST make the service available as part of the federated knowledge graph, a Graph AssetAsset On the Data Provider side, an Asset describes the data set which will be shared or can be consumed by a Data Consumer. pointing to your Remoting Agent endpoint is needed.
POLICY CONSTRAINTS FOR DATA EXCHANGE
In alignment with our commitment to data sovereignty, a specific framework governing the utilization of data within the Catena-X use cases has been outlined. As part of this data sovereignty framework, conventions for access policies, for usage policies and for the constraints contained in the policies have been specified in standard 'CX-0152 Policy Constraints for Data Exchange'. This standard document CX-0152 MUST be followed when providing services or apps for data sharing/consuming and when sharing or consuming data in the Catena-X ecosystem. What conventions are relevant for what roles named in 1.1 AUDIENCE & SCOPE is specified in the CX-0152 standard document as well. CX-0152 can be found in the standard library.
Versioning
Note: Data AssetsAsset On the Data Provider side, an Asset describes the data set which will be shared or can be consumed by a Data Consumer. differentiated only by major version MUST be offered in parallel. The current standard and APIAPI An API is a way for two or more computer programs to communicate with each other. versions mark the start of Life Cycle Management in Catena-X operations. Previous versions are dismissed.
The APIAPI An API is a way for two or more computer programs to communicate with each other. version described in this standard document MUST be published in the property https://w3id.org/catenax/ontology/common#version as version X.Y in dcat:Dataset (http://www.w3.org/ns/dcat#). The requester of an assetAsset On the Data Provider side, an Asset describes the data set which will be shared or can be consumed by a Data Consumer. MUST be able to handle multiple assetsAsset On the Data Provider side, an Asset describes the data set which will be shared or can be consumed by a Data Consumer. for this endpoint, being differentiated only by the version. The requester SHOULD choose the assetAsset On the Data Provider side, an Asset describes the data set which will be shared or can be consumed by a Data Consumer. with the highest compatible version number implemented by themselves. If the requester cannot find a compatible version with their own, the requester MUST terminate the data transfer.
3 ASPECT MODELS
The following Aspect ModelsAspect Model A formal, machine-readable semantic description (expressed with RDF/Turtle) of data accessible from an aspect. Note 1: An Aspect Model must adhere to the Semantic Aspect Meta Model (SAMM) and be compliant with its validity rules. Note 2: Aspect Models are logical data models that can be used to detail a conceptual model to describe the semantics of runtime data related to a concept; elements of an Aspect Model can/should refer to terms of a standardized Business Glossary (if existing). are part of this standard:
- ClassifiedLoadSpectrum, V 1.0.0, urn:bamm:io.catenax.classified_load_spectrum:1.0.0
- RemainingUsefulLife", V1.0.0, urn:bamm:io.catenax.rul:1.0.0##RemainingUsefulLife
This section is normative
3.1 ASPECT MODEL "ClassifiedLoadSpectrum"
3.1.1 INTRODUCTION
The data model "ClassifiedLoadSpectrum" represents the load data of a vehicle component.
The load spectrum is a data set that represents the aggregated loading of a component.
Any kind of loading is covered: loading can be force or torque or revolutions or temperature or event or similar. The load data is classified and counted with specific counting methods.
This standard defines the format for the counted load data, so that the exchange of load data between different partners is possible.
3.1.2 CONTEXT
This section is non-normative
The „ClassifiedLoadSpectrum" contains load data, metadata to interpret this load data and the CX ID of the assembly or component these load data are valid for.
Load spectra counts the loading of a component in classes. Loading can be a change of a state like gearshift, a temperature distribution or the torque acting at a shaft or anything else. In a load spectrum, these loads are classified. The torque acting at a shaft, for example, has an upper and a lower limit: this interval is divided in a number smaller intervals, the classes and torque is sorted is this classes. The counting may be the time the shaft is subjected to the torque or the number of changes of torque classes.
In the standard, arbitrary number of load channels are possible, but only one counting. For each load channel a vector with the acting load classes must be provided. The first entry in the counts vector is the counting of the combination of loads given in the first entries of the load channel vectors. Only load combinations which occur are stored. So the number of data is minimized.
All kinds of load data and events can be covered with the standard. The counting might be time or any kind of numbering like number of events or revolutions.
The metadata block is used to identify the right component in order to interpret the load spectrum. A component is designed for a specific application with a specific loading. To estimate the damage respectively the health of a component, a lifetime model is combined with the load data. The lifetime model is in general property of the component producer. Load data might be measured, simulated or logged during component usage.
The standard covers all classified load spectra, independent of the origin. The origin is stored in the standard.
3.1.3 EXAMPLES
{
"targetComponentID": "urn:uuid:1d161134-8bd4-4253-8735-304852d1d17b",
"metadata": {
"projectDescription": "projectnumber Stadt",
"componentDescription": "GearOil",
"routeDescription": "logged",
"status": {
"date": "2022-08-11T10:42:14.213+01:00",
"operatingHours": 3213.9,
"mileage": 65432
}
},
"header": {
"countingMethod": "TimeAtLevel",
"channels": [
{
"channelName": "TC_SU",
"unit": "unit:degreeCelsius",
"lowerLimit": 0.0,
"upperLimit": 640.0,
"numberOfBins": 128
}
],
"countingValue": "Time",
"countingUnit": "unit:secondUnitOfTime"
},
"body": {
"classes": [
{
"className": "TC_SU-class",
"classList": [
14,
15,
16,
17,
18,
19,
20,
21,
22
]
}
],
"counts": {
"countsName": "Time",
"countsList": [
34968.93,
73972.51,
401315.15,
4675505.56,
2526898.35,
864975.95,
938365.35,
1918920.77,
135387.54
]
}
}
3.1.4 TERMINOLOGY
This section is non-normative
Aspect ModelAspect Model A formal, machine-readable semantic description (expressed with RDF/Turtle) of data accessible from an aspect. Note 1: An Aspect Model must adhere to the Semantic Aspect Meta Model (SAMM) and be compliant with its validity rules. Note 2: Aspect Models are logical data models that can be used to detail a conceptual model to describe the semantics of runtime data related to a concept; elements of an Aspect Model can/should refer to terms of a standardized Business Glossary (if existing). : a formal, machine-readable semantic description (expressed with RDF/turtle) of data accessible from an Aspect.
: Note 1 to entry: An Aspect ModelAspect Model A formal, machine-readable semantic description (expressed with RDF/Turtle) of data accessible from an aspect. Note 1: An Aspect Model must adhere to the Semantic Aspect Meta Model (SAMM) and be compliant with its validity rules. Note 2: Aspect Models are logical data models that can be used to detail a conceptual model to describe the semantics of runtime data related to a concept; elements of an Aspect Model can/should refer to terms of a standardized Business Glossary (if existing). must adhere to the Semantic Aspect Meta Model (SAMM), i.e., it utilizes elements and relations defined in the Semantic Aspect Meta Model and is compliant to the validity rules defined by the Semantic Aspect Meta Model.
: Note 2 to entry: Aspect modelAspect Model A formal, machine-readable semantic description (expressed with RDF/Turtle) of data accessible from an aspect. Note 1: An Aspect Model must adhere to the Semantic Aspect Meta Model (SAMM) and be compliant with its validity rules. Note 2: Aspect Models are logical data models that can be used to detail a conceptual model to describe the semantics of runtime data related to a concept; elements of an Aspect Model can/should refer to terms of a standardized Business Glossary (if existing). are logical data models which can be used to detail a conceptual model in order to describe the semantics of runtime data related to a concept. Further, elements of an Aspect modelAspect Model A formal, machine-readable semantic description (expressed with RDF/Turtle) of data accessible from an aspect. Note 1: An Aspect Model must adhere to the Semantic Aspect Meta Model (SAMM) and be compliant with its validity rules. Note 2: Aspect Models are logical data models that can be used to detail a conceptual model to describe the semantics of runtime data related to a concept; elements of an Aspect Model can/should refer to terms of a standardized Business Glossary (if existing). can/should refer to terms of a standardized Business Glossary (if existing).
[Source: Catena-X, CX-0002:v1.2]
-
"Classified Load Spectrum": Aspect modelAspect Model A formal, machine-readable semantic description (expressed with RDF/Turtle) of data accessible from an aspect. Note 1: An Aspect Model must adhere to the Semantic Aspect Meta Model (SAMM) and be compliant with its validity rules. Note 2: Aspect Models are logical data models that can be used to detail a conceptual model to describe the semantics of runtime data related to a concept; elements of an Aspect Model can/should refer to terms of a standardized Business Glossary (if existing).
-
"targetComponentID": CX -ID of the assembly or component for which the load spectrum is valid for. It is necessary to identify the specific component.
-
"metadata"/"Metadata": property/entity; Information on component, vehicle, load data origin and vehicle status
-
"componentDescription": property; identifier, might be used to find the right lifetime model
-
"projectDescription": property; identifier, might be used for information on specific vehicle
-
"routeDescription": property; identifier, might be used for information on specific application
-
"status"/"StatusEntity": property/entity; actual vehicle status
-
"date": property; actual date at which the load spectrum is provided
-
"mileage": property; mileage which the load spectrum covers, the unit is [km]
-
"operatingHours": property; number of operating hours which the load spectrum covers
-
"header"/"HeaderEntity": property/entity; classification information
-
"countingMethod": property; enumeration describing the kind of counting: "Rainflow", "LRD", "EventCount", "TimeAtLevel", "RangeCount", "PeakCount", "MaximumCount".
-
"countingValue": property; optional, for example "Time", if time is counted.
-
"countingUnit" : property; dependent on counting value "unit: s" for time
-
"channels"/"LoadChannelEntity" property/entity; list of load channels. Each list entry contains
-
"channelName": property; identifier of channel
-
"unit": property; unit of the load, for example "unit: degreeCelsius" or "unit: Nm"
-
"lowerLimit": property; lower limit of the load value
-
"upperLimit": property; upper limit of the load value
-
"numerOfBins": property; number of load classes
-
"binLimits": property; optional, if a non-equidistant divisio
-
"body"/"BodySets": property/entity; lists of load dat
-
"classes"/"ClassListEntity": property/entity; list of load channels, each entry in the list contains
-
"className" : here the channel is characterized by channel name. The name ics extended by "-class". For a rainflow counting, a load channel has two class lists, the channel name must be extended with "_from-class" and "_to-class"
-
"classList": list of the load data
-
"counts"/"CountsEntity": property/entity; counts name and list
-
"countsName": Name of counting, for example "NumberOfRevolutions" or just "Counts"
-
"countsList": property; list of the counting according to the classes in same position in "classList"
-
"residuum"/"ResiduumEntity": property/entity; for rainflow counted load spectra, a residuum stores the unclosed hysteresis loops.
-
"residuumClassName": property; the name is according to the load channel name
-
"residuumClassList": property; the list of turning point classes belonging to unclosed hysteresis loops
Additional terminology used in this standard can be looked up in the glossary on the association homepage.
3.1.5 SPECIFICATIONS ARTIFACTS
The modeling of the semantic model specified in this document was done in accordance to the "semantic driven workflow" to create a submodel template specification SMT.
This aspect modelAspect Model A formal, machine-readable semantic description (expressed with RDF/Turtle) of data accessible from an aspect. Note 1: An Aspect Model must adhere to the Semantic Aspect Meta Model (SAMM) and be compliant with its validity rules. Note 2: Aspect Models are logical data models that can be used to detail a conceptual model to describe the semantics of runtime data related to a concept; elements of an Aspect Model can/should refer to terms of a standardized Business Glossary (if existing). is written in BAMM 1.0.0 as a modeling language.
Like all Catena-X data models, this model is available in a machine-readable format on GitHub conformant to CX-0003.
3.1.6 LICENSE
This Catena-X data model is made available under the terms of the Creative Commons Attribution 4.0 International (CC-BY-4.0) license, which is available at Creative Commons.
3.1.7 IDENTIFIER OF SEMANTIC MODEL
The semantic model has the unique identifier:
urn:bamm:io.catenax.classified_load_spectrum:1.0.0
This identifier MUST be used by the data provider to define the semantics of the data being transferred.
3.1.8 FORMATS OF SEMANTIC MODEL
3.1.8.1 RDF TURTLE
The rdf turtle file, an instance of the Semantic Aspect Meta Model, is the master for generating additional file formats and serializations. The file can be found here:
The open-source command line tool of the Eclipse Semantic Modeling Framework is used for generation of other file formats like for example a JSON Schema, aasx for Asset Administration ShellAsset Administration Shell The AAS is a digital representation of an asset; it is a form of a digital twin. Submodel Template or a HTML documentation.
3.1.8.2 JSON SCHEMA
A JSON Schema can be generated from the RDF Turtle file. The JSON Schema defines the Value-Only payload of the Asset Administration ShellAsset Administration Shell The AAS is a digital representation of an asset; it is a form of a digital twin. for the APIAPI An API is a way for two or more computer programs to communicate with each other. operation "GetSubmodel".
3.1.8.3 AASX
An AASX file can be generated from the RDF Turtle file. The AASX file defines one of the requested artifacts for a Submodel Template Specification conformant to [SMT].
Note: As soon as the specification V3.0 of the Asset Administration ShellAsset Administration Shell The AAS is a digital representation of an asset; it is a form of a digital twin. specification is available an update will be provided. Template or a HTML documentation.
3.2 ASPECT MODEL "RemainingUsefulLife"
3.2.1 INTRODUCTION
The data model Remaining Useful Life contains the two relevant values to describe the expected remaining life of a vehicle, remaining running distance and remaining operating hours.
The data model is used for vehicle parts and vehicle components which cannot be visually assessed but need the loading information combined with a damage model to estimate the health of the component.
3.2.2 CONTEXT
This section is non-normative
Remaining useful Life is describing the actual health of a vehicle component. Remaining useful Life is defined for vehicle and vehicle components; the values are "remaining running distance" and "remaining operating hours". As it is a short-term property, the status of determination is part of the standard. Remaining useful Life is the result of a service determining the health of a vehicle component from the loading the component was subjected to. This loading might before example measured, simulate or estimated, this information on the origin of the loading is part of the standard.
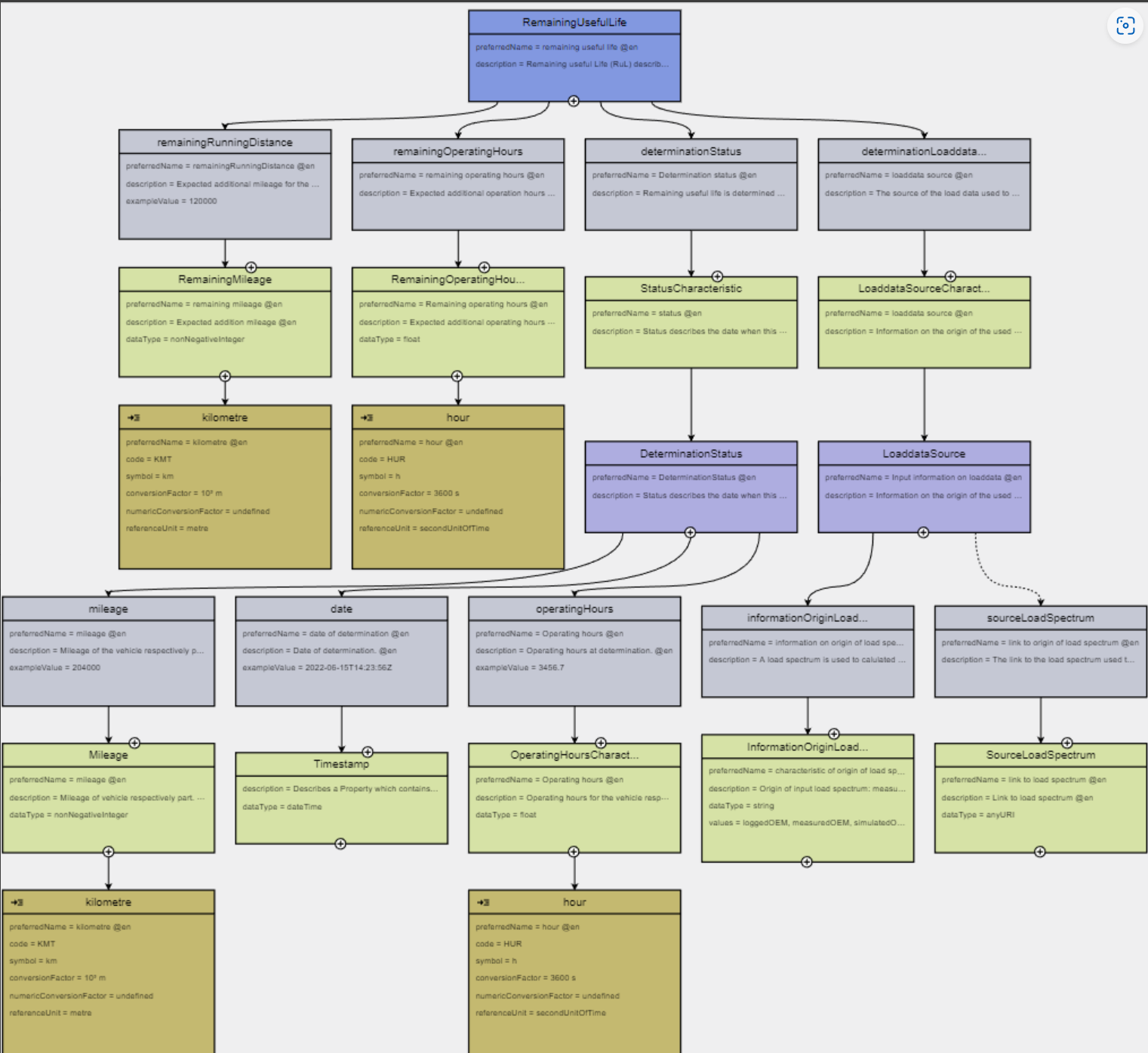 Figure 1: Overview
Figure 1: Overview
3.2.3 EXAMPLES
{
"remainingOperatingHours": 2500,
"remainingRunningDistance": 150000,
"determinationStatus": {
"date": "2022-06-15T14:23:56Z",
"operatingHours": 3456.7,
"mileage": 204000
},
"determinationLoaddataSource": {
"informationOriginLoadSpectrum": "loggedOEM"
}
}
3.2.4 TERMINOLOGY
This section is non-normative
Aspect ModelAspect Model A formal, machine-readable semantic description (expressed with RDF/Turtle) of data accessible from an aspect. Note 1: An Aspect Model must adhere to the Semantic Aspect Meta Model (SAMM) and be compliant with its validity rules. Note 2: Aspect Models are logical data models that can be used to detail a conceptual model to describe the semantics of runtime data related to a concept; elements of an Aspect Model can/should refer to terms of a standardized Business Glossary (if existing). : a formal, machine-readable semantic description (expressed with RDF/turtle) of data accessible from an Aspect.
: Note 1 to entry: An Aspect ModelAspect Model A formal, machine-readable semantic description (expressed with RDF/Turtle) of data accessible from an aspect. Note 1: An Aspect Model must adhere to the Semantic Aspect Meta Model (SAMM) and be compliant with its validity rules. Note 2: Aspect Models are logical data models that can be used to detail a conceptual model to describe the semantics of runtime data related to a concept; elements of an Aspect Model can/should refer to terms of a standardized Business Glossary (if existing). must adhere to the Semantic Aspect Meta Model (SAMM), i.e., it utilizes elements and relations defined in the Semantic Aspect Meta Model and is compliant to the validity rules defined by the Semantic Aspect Meta Model.
: Note 2 to entry: Aspect modelAspect Model A formal, machine-readable semantic description (expressed with RDF/Turtle) of data accessible from an aspect. Note 1: An Aspect Model must adhere to the Semantic Aspect Meta Model (SAMM) and be compliant with its validity rules. Note 2: Aspect Models are logical data models that can be used to detail a conceptual model to describe the semantics of runtime data related to a concept; elements of an Aspect Model can/should refer to terms of a standardized Business Glossary (if existing). are logical data models which can be used to detail a conceptual model in order to describe the semantics of runtime data related to a concept. Further, elements of an Aspect modelAspect Model A formal, machine-readable semantic description (expressed with RDF/Turtle) of data accessible from an aspect. Note 1: An Aspect Model must adhere to the Semantic Aspect Meta Model (SAMM) and be compliant with its validity rules. Note 2: Aspect Models are logical data models that can be used to detail a conceptual model to describe the semantics of runtime data related to a concept; elements of an Aspect Model can/should refer to terms of a standardized Business Glossary (if existing). can/should refer to terms of a standardized Business Glossary (if existing).
[Source: Catena-X, CX-0002:v1.2]
- RemainingRunningDistance: The estimated number of kilometers, the vehicle can drive without expectable failure of the component. This is an integer number, the unit is [km].
- Remaining operating hours: Estimated number of operating hours of the vehicle without expectable failure of the component. Floating number, unit is [h].
- determinationLoaddataSource: The remaining life is estimated from the loading the component was subjected to. The loading of the component might be logged during vehicle life or simulated or estimated: this information on the origin is stored here. If available, the URL of the loadspectrum can be stored here.
- determinationStatus : Comprising "date", "mileage", "operatingHours", the timestamp the remainingUsefulLife was calculated and the according mileage and operating hours of the vehicle.
- sourceLoadSpectrum: if available, the URL of the used load spectrum
- informationOriginLoadSpectrum: enumeration of possible loaddata sources:
- "loggedOEM": the data are collected during usage and provided on OEM side
- "measuredOEM": load data are measured on OEM side
- "simulatedOEM": load data are simulated on OEM side
- "loggedSupplier": the data are collected during usage and provided on supplierSupplier In the context of OSim, the producer of goods. side
- "measuredSupplier": load data are measured on supplierSupplier In the context of OSim, the producer of goods. side
- "simulatedSupplier": load data are simulated on supplierSupplier In the context of OSim, the producer of goods. side
- "otherOrigin": any other origin of load data, may be not even a load spectrum
Additional terminology used in this standard can be looked up in the glossary on the association homepage.
3.2.5 SPECIFICATIONS ARTIFACTS
The modeling of the semantic model specified in this document was done in accordance to the "semantic driven workflow" to create a submodel template specification SMT.
This aspect modelAspect Model A formal, machine-readable semantic description (expressed with RDF/Turtle) of data accessible from an aspect. Note 1: An Aspect Model must adhere to the Semantic Aspect Meta Model (SAMM) and be compliant with its validity rules. Note 2: Aspect Models are logical data models that can be used to detail a conceptual model to describe the semantics of runtime data related to a concept; elements of an Aspect Model can/should refer to terms of a standardized Business Glossary (if existing). is written in BAMM 1.0.0 as a modeling language.
Like all Catena-X data models, this model is available in a machine-readable format on GitHub conformant to CX-0003.
3.2.6 LICENSE
This Catena-X data model is made available under the terms of the Creative Commons Attribution 4.0 International (CC-BY-4.0) license, which is available at Creative Commons.
3.2.7 IDENTIFIER OF SEMANTIC MODEL
The semantic model has the unique identifier:
urn:bamm:io.catenax.rul:1.0.0##RemainingUsefulLife
3.2.8 FORMATS OF SEMANTIC MODEL
3.2.8.1 RDF TURTLE
The rdf turtle file, an instance of the Semantic Aspect Meta Model, is the master for generating additional file formats and serializations.
The ttl file can be found here:
The open-source command line tool of the Eclipse Semantic Modeling Framework is used for generation of other file formats like for example a JSON Schema, AASX for Asset Administration ShellAsset Administration Shell The AAS is a digital representation of an asset; it is a form of a digital twin. Submodel Template or a HTML documentation.
3.2.8.2 JSON SCHEMA
A JSON Schema can be generated from the RDF Turtle file. The JSON Schema defines the Value-Only payload of the Asset Administration ShellAsset Administration Shell The AAS is a digital representation of an asset; it is a form of a digital twin. for the APIAPI An API is a way for two or more computer programs to communicate with each other. operation "GetSubmodel".
3.2.8.3 AASX
An AASX file can be generated from the RDF Turtle file. The AASX file defines one of the requested artifacts for a Submodel Template Specification conformant to [SMT].
Note: As soon as the specification V3.0 of the Asset Administration ShellAsset Administration Shell The AAS is a digital representation of an asset; it is a form of a digital twin. specification is available an update will be provided.
4 APPLICATION PROGRAMMING INTERFACES
This section is normative
This section only applies if using the notification based APIAPI An API is a way for two or more computer programs to communicate with each other.
4.1 ENDURANCE PREDICTOR API
4.1.1 PRECONDITIONS AND DEPENDENCIES
The Endurance Predictor service was designed with interoperability in mind, thus the communication in both directions (input/input) fully supports the Catena-X Notification standard. These aspects are also covered by Catena-X ontologies. For this purpose, in the behaviour_ontology, which is part of the Standard CX-0084:v1.2 is defined accordingly.
The two APIsAPI An API is a way for two or more computer programs to communicate with each other. described support the implementation of the dynamic behavior (i.e., service) of components (e.g., engine, gearbox..) in a digital behavior twin. As the process is asynchronous, there are two APIsAPI An API is a way for two or more computer programs to communicate with each other. for different types of participants in the network.
- APIAPI An API is a way for two or more computer programs to communicate with each other. endpoint to be provided by a Service Provider providing a service to predict the expected lifetime of a product based on load spectra.
- APIAPI An API is a way for two or more computer programs to communicate with each other. endpoint to be provided by a Service Requester application or participant to receive the outcome of such an analysis in an asynchronous manner.
It is a non-central APIAPI An API is a way for two or more computer programs to communicate with each other., which can be implemented for various components. It relies on a load spectrum as input in order to calculate and return the corresponding RUL value. The basic idea for the functionality of this APIAPI An API is a way for two or more computer programs to communicate with each other. has been derived from CX-0023:v1.2 Notification APIAPI An API is a way for two or more computer programs to communicate with each other..
As already mentioned in the Introduction, this standard provides the specification of the HTTPHTTP HTTP is an application-layer protocol for transmitting hypermedia documents (such as HTML). It was designed for communication between web browsers and web servers, but can also be used for other purposes. RESTREST An architectural style for designing networked applications. APIAPI An API is a way for two or more computer programs to communicate with each other. endpoint to request (with an according Load Spectrum as input) and sending RUL value via the Catena X Dataspace. Without this APIAPI An API is a way for two or more computer programs to communicate with each other. an interoperability between different application, with an aim to receive RUL data, is not given.
4.1.2 API SPECIFICATION
4.1.2.1 API ENDPOINTS AND RESOURCES
The notification APIAPI An API is a way for two or more computer programs to communicate with each other. MUST be implemented as specified in the [openAPI] documentation as stated here:
• POST /apiAPI An API is a way for two or more computer programs to communicate with each other./v1/routine/notification
In fact, it is OPTIONAL to implement the endpoint paths exactly as described above. The reason is that those endpoints are not called from any supply chain partner directly. Rather, they are called from the Dataspace Connector or a similar IDSAIDSA The IDSA is an organization working to create the future of the global digital economy with International Data Spaces (IDS): a secure, sovereign system of data sharing where participants can realize the full value of their data. compliant connector as part of its data assetsAsset On the Data Provider side, an Asset describes the data set which will be shared or can be consumed by a Data Consumer.. In that sense, it is just important to implement endpoints that can process the defined request body and respond with the HTTPHTTP HTTP is an application-layer protocol for transmitting hypermedia documents (such as HTML). It was designed for communication between web browsers and web servers, but can also be used for other purposes. status codes and - if required - reply with the defined response body.
The IDSAIDSA The IDSA is an organization working to create the future of the global digital economy with International Data Spaces (IDS): a secure, sovereign system of data sharing where participants can realize the full value of their data. compliant data assetsAsset On the Data Provider side, an Asset describes the data set which will be shared or can be consumed by a Data Consumer. will act similar to a reverse proxy for the notification endpoints, therefore rather the data assetsAsset On the Data Provider side, an Asset describes the data set which will be shared or can be consumed by a Data Consumer. are of significance, which should be exposed towards Catena-X through the Data Offer Catalogues in the Dataspace Connector or any other IDSA ProtocolIDSA Protocol The protocol used for data exchange in an International Dataspace; this includes contract negotiation. compatible connector.
4.1.2.2 AVAILABLE DATA TYPES
The APIAPI An API is a way for two or more computer programs to communicate with each other. MUST use JSON as the payload transported. The APIsAPI An API is a way for two or more computer programs to communicate with each other. payload consists of a general notification header and a use case specific content dictionary. The request and response are linked by the unique notificationID.
4.1.2.3 NOTIFICATION REQUEST PAYLOAD STRUCTURE
The main part of the content dictionary MUST follow the specification in section 3.1 "Semantic Model: Classified Load Spectrum" as the load spectrum itself is given as the main input towards the endurance predictor.
{
"header": {
"notificationID": "notification-UUID",
"senderBPN": "BPNL0000000000",
"senderAddress": "https://abc.com",
"recipientAddress":"https://connector-xxxx/BPNL000000",
"recipientBPN": "BPNL0000000",
"severity": "MINOR",
"status": "SENT",
"targetDate": "target-date",
"timeStamp": "time-stamp",
"classification": "RemainingUsefulLifePredictor",
"respondAssetId": "urn:pilot:service:EndurancePredictorEstimationNotification"
},
"content": {
"requestRefId": " notification-receipt ",
"endurancePredictorInputs": [
{
"componentId": " notification-receipt ",
"classifiedLoadSpectrumGearOil": {
<load spectrum as per standard as specified in section 3.1: Semantic Model: Classified Load Spectrum>
},
"classifiedLoadSpectrumGearSet": {
<load spectrum as per standard as specified in section section 3.1: Classified Load Spectrum>
}
}
]
}
}
4.1.2.4 NOTIFICATION RESPONSE PAYLOAD STRUCTURE
The main part of the content dictionary MUST follow the specification in section 3.2 "Semantic Model: Remaining Useful Life" as endurance predictor output MUST follow the semantics described in the corresponding model:
{
"header": {
"referencedNotificationID": "notification-UUID",
"senderBPN": "BPNL0000000",
"senderAddress": "https://connector-xy.com/BPNL0000000",
"classification": "EndurancePredictorResult",
"recipientAddress": "https://connector-xx.com",
"recipientBPN": "BPNL0000000",
"severity": "MINOR",
"status": "SENT",
"targetDate": "target-date",
"timeStamp": "time-stamp",
"respondAssetId": "urn:pilot:service:EndurancePredictorEstimationNotification"
},
"content": {
"componentType": "GearBox",
"endurancePredictorOutputs": [
{
"componentType": "GearSet",
"componentId": " notification-receipt ",
"remainingUsefulLife": {
<RuL as per standard as specified in section 3.2: Semantic Model: Remaining Useful Life>
}
}
]
}
}
4.1.2.5 NOTIFICATION RESPONSE ERROR PAYLOAD STRUCTURE
{
"header": {
"referencedNotificationID": "notification-UUID",
"senderBPN": "BPNL0000000",
"senderAddress": "https://connector-xy.com/BPNL0000000",
"classification": "EndurancePredictorResult",
"recipientAddress": "https://connector-xx.com",
"recipientBPN": "BPNL0000000",
"severity": "MINOR",
"status": "SENT",
"targetDate": "target-date",
"timeStamp": "time-stamp",
"respondAssetId": "urn:pilot:service:EndurancePredictorEstimationNotification"
},
"content": {
"componentType": "GearBox",
"type": "Error",
"message": "Error Message",
"endurancePredictorOutputs": []
}
}
4.1.3 EDC DATA ASSET STRUCTURE
When using the Tractus-X EDCTractus-X EDC The Tractus-X Eclipse Dataspace Connector (Tractus-X EDC) is a reference implementation for a connector conformant to CX-0018 and acts as a de-facto standard/reference implementation within Catena-X; other CX-0018-conformant connectors are also valid options. (Eclipse Dataspace Connector), the following assetAsset On the Data Provider side, an Asset describes the data set which will be shared or can be consumed by a Data Consumer. MUST be registered by the specific roles in this process. Other connectors implementing the IDSA ProtocolIDSA Protocol The protocol used for data exchange in an International Dataspace; this includes contract negotiation. require a similar data assetAsset On the Data Provider side, an Asset describes the data set which will be shared or can be consumed by a Data Consumer. with the same structure and provisioning towards Catena-X.
4.1.3.1 SERVICE CONSUMER
As an application provider or an data consumer calling an endurance predictor of another participant an APIAPI An API is a way for two or more computer programs to communicate with each other. for asynchronous receival of the result is required. The corresponding data assetAsset On the Data Provider side, an Asset describes the data set which will be shared or can be consumed by a Data Consumer. MUST look like the following:
{
"@context": {
"cx-common": "https://w3id.org/catenax/ontology/common#"
},
"asset": {
"@type": "Asset",
"@id": "endurancePredictorResult-receipt",
"properties": {
"dct:type": {
"@id": "EndurancePredictorResult"
},
"cx-common:name": "endurancePredictorResult-receipt",
"cx-common:description": "Asset to receive endurance predictor results.",
"cx-common:version": "1.0",
"cx-common:contenttype": "application/json"
}
},
"dataAddress": {
"@type": "DataAddress",
"type": "HttpData",
"baseUrl": "https://{{httpServerWhichOffersTheHttpEndpoint}}/api/v1/routine/notification",
"proxyMethod": "true",
"proxyQueryParams": "true",
"proxyBody": "true"
}
}
The variable {{httpServerWhichOffersTheHttpEndpoint}} MUST be set to the HTTPHTTP HTTP is an application-layer protocol for transmitting hypermedia documents (such as HTML). It was designed for communication between web browsers and web servers, but can also be used for other purposes. server that offers the endpoint. The path /apiAPI An API is a way for two or more computer programs to communicate with each other./v1/routine/notification MAY align with the HTTPHTTP HTTP is an application-layer protocol for transmitting hypermedia documents (such as HTML). It was designed for communication between web browsers and web servers, but can also be used for other purposes. POST path as stated in 4.1.2.1. In that sense it can change dependent on the endurance application.
4.1.3.2 SERVICE PROVIDER
As an service provider or data provider providing an endpoint for an endurance predictor service, an APIAPI An API is a way for two or more computer programs to communicate with each other. for receival of the request including the load spectrum data is required. The corresponding data assetAsset On the Data Provider side, an Asset describes the data set which will be shared or can be consumed by a Data Consumer. MUST look like the following:
{
"@context": {
"cx-common": "https://w3id.org/catenax/ontology/common#"
},
"asset": {
"@type": "Asset",
"@id": "endurancePredictorRequest-receipt",
"properties": {
"dct:type": {
"@id": "EndurancePredictorRequest"
},
"cx-common:name": "endurancePredictorRequest-receipt",
"cx-common:description": "Asset to receive endurance predictor requests incl. load spectrum.",
"cx-common:version": "1.0",
"cx-common:contenttype": "application/json"
}
},
"dataAddress": {
"@type": "DataAddress",
"type": "HttpData",
"baseUrl": "https://{{httpServerWhichOffersTheHttpEndpoint}}/api/v1/routine/notification",
"proxyMethod": "true",
"proxyQueryParams": "true",
"proxyBody": "true"
}
}
The variable {{httpServerWhichOffersTheHttpEndpoint}} MUST be set to the HTTPHTTP HTTP is an application-layer protocol for transmitting hypermedia documents (such as HTML). It was designed for communication between web browsers and web servers, but can also be used for other purposes. server that offers the endpoint. The path /apiAPI An API is a way for two or more computer programs to communicate with each other./v1/routine/notification MAY align with the HTTPHTTP HTTP is an application-layer protocol for transmitting hypermedia documents (such as HTML). It was designed for communication between web browsers and web servers, but can also be used for other purposes. POST path as stated in 4.1.2.1. In that sense it can change dependent on the endurance application.
4.1.4 ERROR HANDLING
The following httpHTTP HTTP is an application-layer protocol for transmitting hypermedia documents (such as HTML). It was designed for communication between web browsers and web servers, but can also be used for other purposes. response codes MUST be defined for HTTPHTTP HTTP is an application-layer protocol for transmitting hypermedia documents (such as HTML). It was designed for communication between web browsers and web servers, but can also be used for other purposes. POST endpoint for the Endurance Predictor endpoint.
| Code | Description |
|---|---|
| 202 | Accepted |
| 400 | Request body was malformed |
5 REFERENCES
5.1 NORMATIVE REFERENCES
- CX–0018:v3.0 Dataspace Connectivity
- CX-0023:v1.2 Notification APIAPI An API is a way for two or more computer programs to communicate with each other. (only if using the notification based APIAPI An API is a way for two or more computer programs to communicate with each other.)
- CX-0067:v1.1 Ontology Models to realize federated query in Catena-X (only if using the Knowledge Agent)
- CX-0084:v1.2 Federated Queries in Data Spaces (Knowledge Agent)
- CX-0152:v1.0 Policy Constraints for Data Exchange
5.2 NON-NORMATIVE REFERENCES
This section is non-normative
Legal
Copyright © 2026 Catena-X Automotive Network e.V. All rights reserved. For more information, please see Catena-X Copyright Notice.